


Why are Ensemble Methods used in Machine Learning?
Ensemble methods are techniques that create multiple models and then combine them to produce improved results. Ensemble methods usually produce more accurate solutions than a single model would.
Types of Ensemble Methods :
Majority Voting
Bagging
Boosting
Gradient Boosting
Random Forests
Stacking
Majority Voting-
The classifier will make the prediction based on the majority vote.
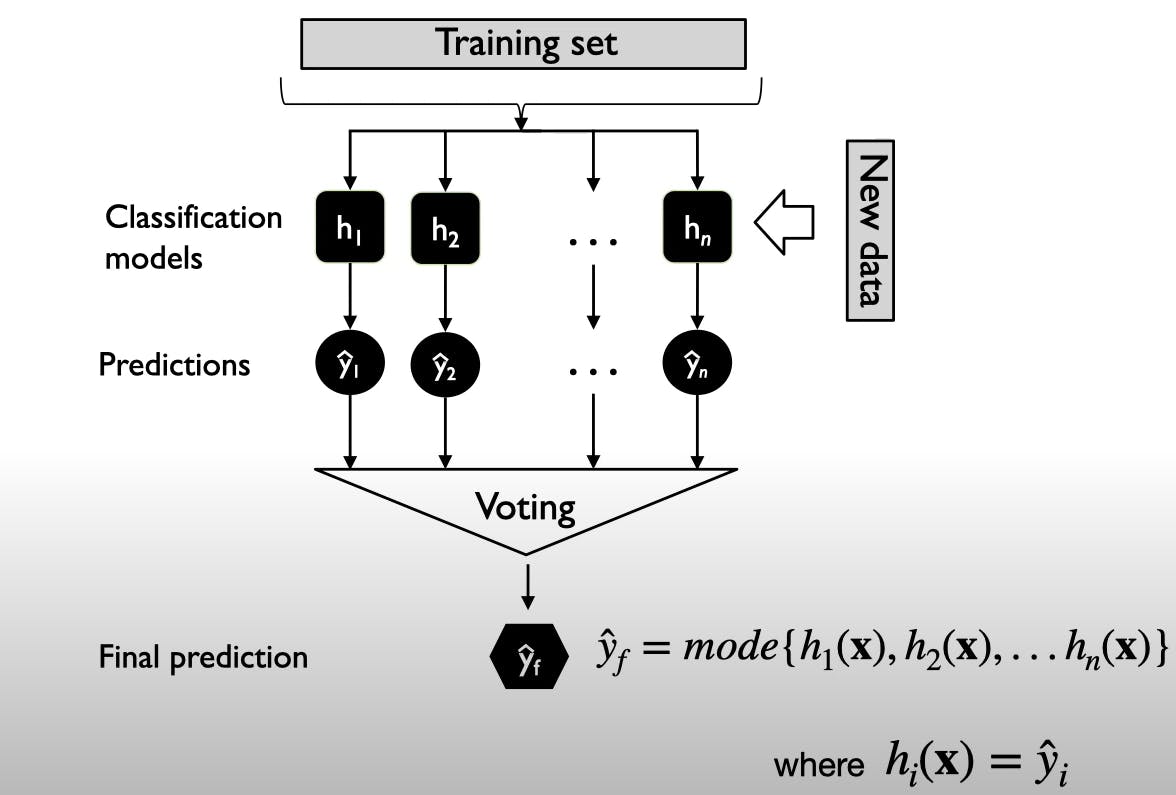 There is a training set and "n" number of classifiers and each classifier is trained on the training set, and then the predictions are made.
For one new data point, we have "n" predictions and then we have a voting scheme.
The majority voting is used to decide what the final prediction is.
There is a training set and "n" number of classifiers and each classifier is trained on the training set, and then the predictions are made.
For one new data point, we have "n" predictions and then we have a voting scheme.
The majority voting is used to decide what the final prediction is.
y^i --> Output Prediction
It can be used for classification or regression problems.
The errors of all the classifiers are uncorrelated. So, it performs better than a single classifier.
Regression Voting Ensemble: Predictions are the average of contributing models.
Classification Voting Ensemble: Predictions are the majority vote of contributing models.
In classification, a hard voting ensemble involves summing the votes for crisp class labels from other models and predicting the class with the most votes. A soft voting ensemble involves summing the predicted probabilities for class labels and predicting the class label with the largest sum probability.
Bagging (Bootstrap Aggregating) -
Algorithm:
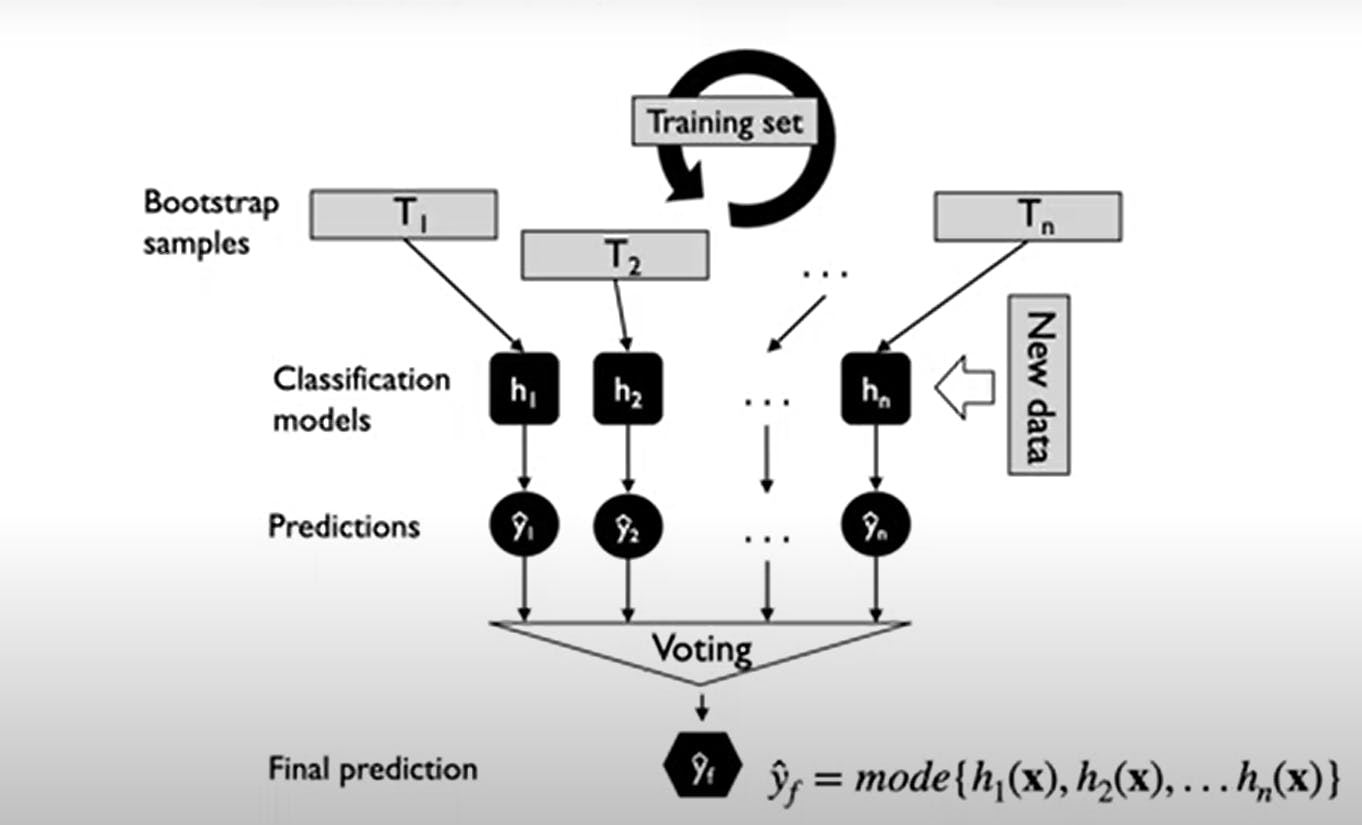
Let "n" be a number of bootstrap samples (i.e number of rounds).
for i=1 to n : Draw bootstrap samples of size "m" from the dataset. Train base classifier "h" on the bootstrap samples.
- Prediction will be done by Majority Voting.
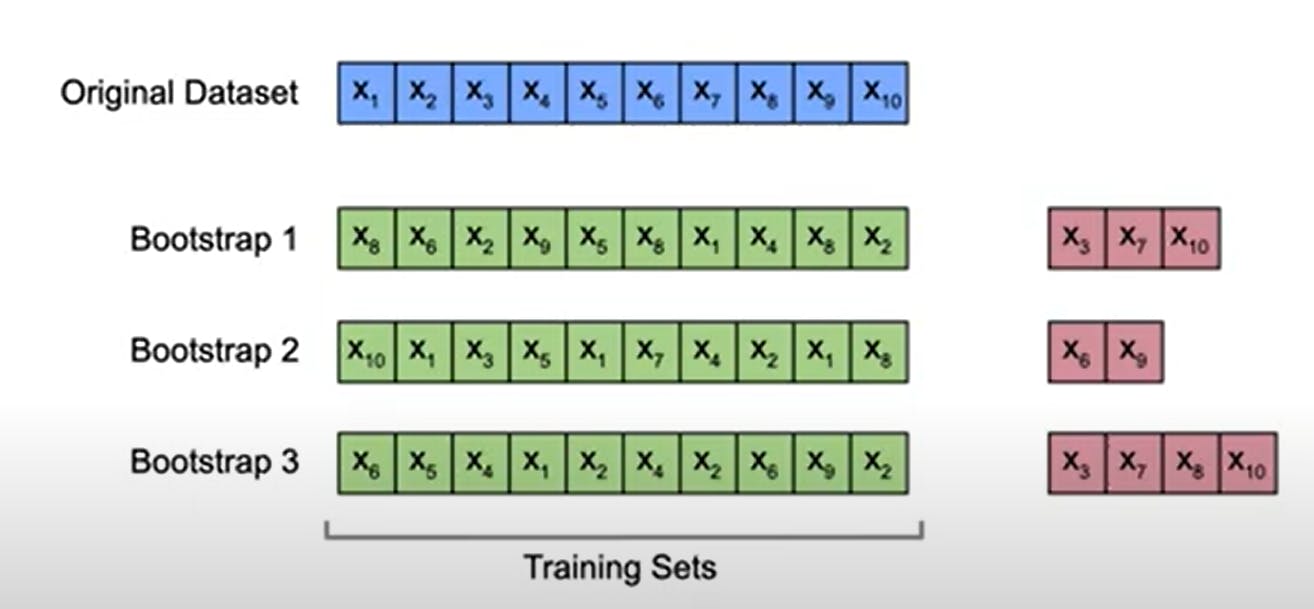 Consider, training dataset of size "m" and each bootstrap sample will also have size "m".
Consider, training dataset of size "m" and each bootstrap sample will also have size "m".
Bootstrap sampling is drawing data points from the dataset with replacements.
Some records will be duplicated in the bootstrap dataset. Randomly sampling from the training set with a uniform distribution just equal weight for sampling.
For each bootstrap sample, a classifier is fit independently. All the bootstrap samplings can be done in parallel.
Why is Bootstrapping used?
Helps to reduce bias-variance decomposition which is related to overfitting and underfitting.
Loss = Bias + Variance + Noise
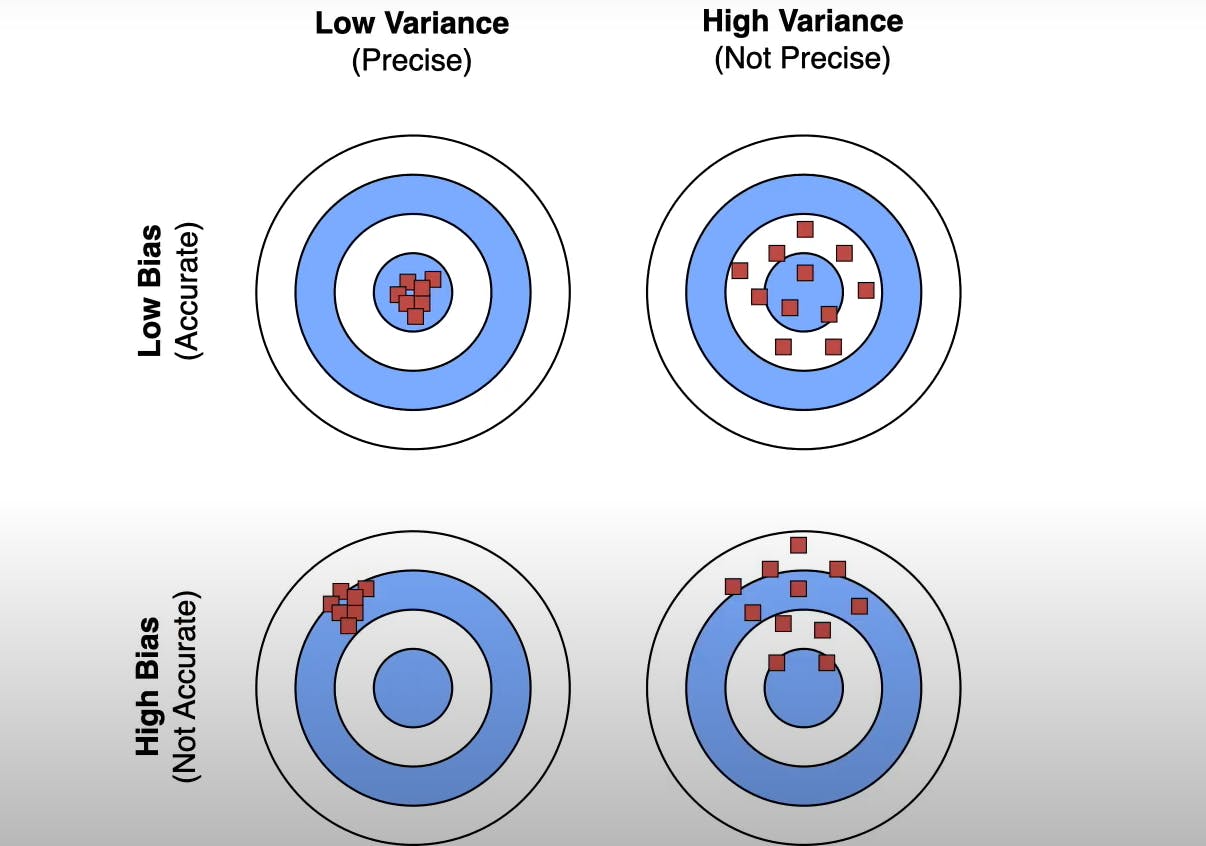 The key idea behind bagging is averaging over high variance models.
The key idea behind bagging is averaging over high variance models.
The bagging method uses unpruned decision trees as the base classifiers.
Boosting -
It is used for high bias models with low variance because we look at very simple decision tree stumps, and we boost these decision tree stumps that have a high bias to get a better performance out of the models.
Types of Boosting -
Adaptive Boosting (Adaboost)
Gradient Boosting (LightGBM, XGBoost, GradientBoostingClassifier)
In general boosting, there is a dependency between the rounds.
We start with the training dataset, and we fit classifier 1 and then based on classifier 1 predictions we weigh the training sample. The second classifier gets these weighted training examples and so on.
The weighting depends on previous classifier predictions.
- Initialize a weight vector with uniform weights.
Loop
- The loop goes through different rounds of the boosting procedure and in each round we apply a weak learner to weighted training examples or can draw bootstrap samples with weighted probability.
- Increase weight for misclassified examples.
- Weighted (Majority) voting on trained classifiers.
Note - Weak learner is slightly better than random guessing (e.g. Decision Tree stump)
Adaboost:-
Initialize the number of Adaboost rounds (k).
Initialize the training dataset (D).
Initialize the weights (w^i) = 1/n (n --> Number of training data point).
For the number of Adaboost rounds:
Normalize the weights (training sample weight/sum of weights)
Fit weak learner
Then we compute the error
If error > 0.5, then stop. (early stopping, as performance is worse than random guessing)
Weights are calculated (Alpha is used) [Alpha is small if the error is large]
The weighted values are then given as an input to the second classifier and so on.
Prediction based on the majority of votes is made.
Gradient Boosting:-
It is among the most widely used machine learning algorithms for working with tabular datasets.
Gradient boosting is somewhat similar to Adaboost -
Trees are fit sequentially to improve the error of previous trees. (Slightly different from Adaboost)
Boost weak learners to the strong learners.
Adaboost/Gradient boosting is harder to parallelize as compared to other ensemble methods.
Note - We do not have weights for misclassified examples, the gradient boosting does not use weights for training examples as well as classifiers.
Instead of majority voting, we are adding this to different predictions.
We do not use decision tree stumps, instead use tree root node in the first iteration, and then we use deeper trees and the consequent iterations.
Conceptual Overview :
Construct base tree (Just a root node)
Build next tree based on errors of the previous tree
Combine trees from step1 with trees from step2. Go back to step2.
---- XGBoost:-
They use several techniques to make gradient boosting more efficient.
Exact greedy (It checks all the possible splits of the continuous features)
Approximate global (Can distribute large datasets across different computers)
Out-of-core (The whole dataset should not be in memory, it supports having large datasets on disk)
Sparsity aware (deal with missing feature values)
Parallel
---- LightGBM:-
Both XGBoost and LightGBM support histogram-based algorithms for split finding. This speeds up training and reduces memory usage.
Random Forests:
Most widely used Machine Learning algorithms in applied research areas as they are very easy to train. They do not require much hyperparameter tuning.
Random Forests = Bagging with trees (Bootstrap sampling)+random feature subsets
Voting in classification and Averaging in regression.
Weaker trees
Less similar trees
Stacking:
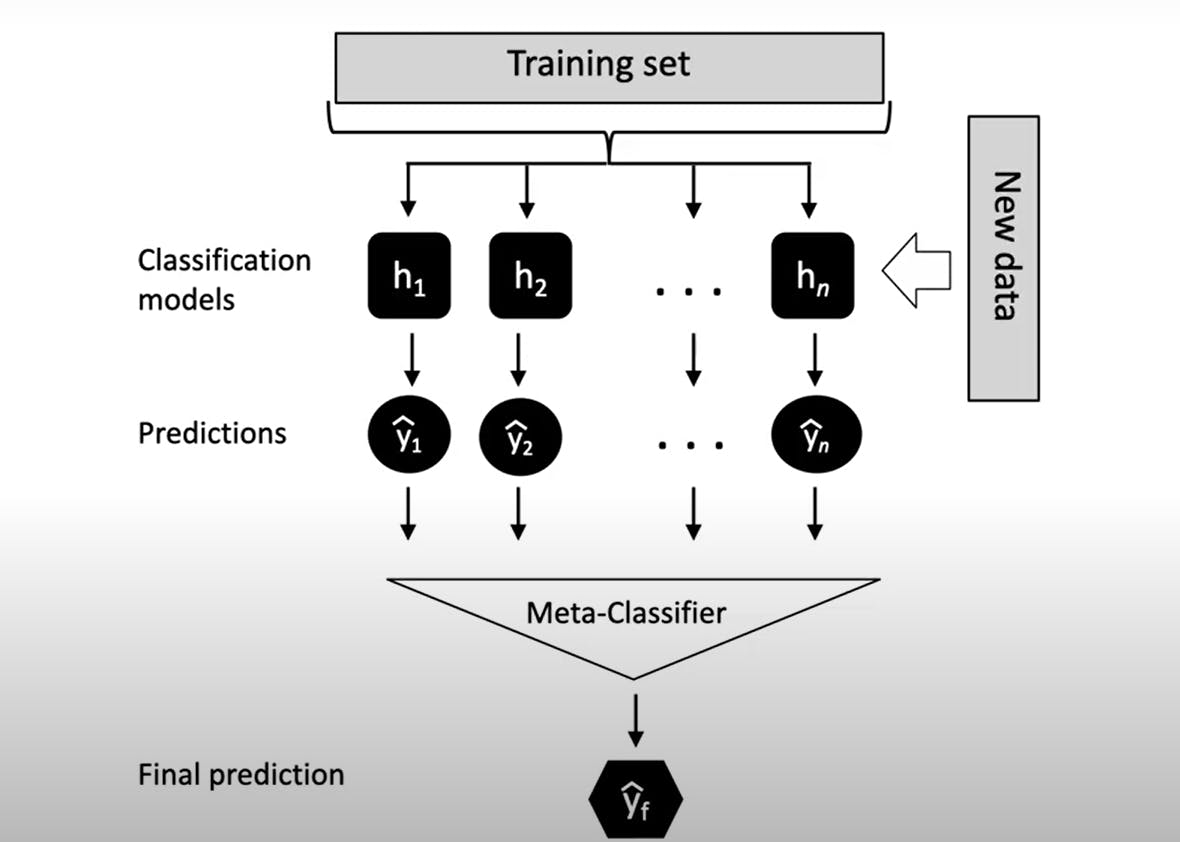
The training set is given as an input to the "n" number of classifiers and we fit different classification models on this dataset. Different classifiers can be used. Each of them would return predictions of these class labels, and then we fit the second-level classifier. Then, these will return a final prediction.
Problem -
The method is very prone to overfitting.
In order to reduce overfitting, cross-validation methods are used.
Hope you found it helpful 😊