


What is Machine Learning?
(Beginners Definition) The field of study where we give machines the ability to learn without being explicitly programmed.
What are the types of Machine Learning?
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
What is Supervised Machine Learning?
Supervised Learning is the type of machine learning in which machines are trained using well "labeled" training data, and on basis of that data, machines predict the output. Supervised Learning is a process of providing input data as well as correct output data to the machine learning model.
What is Unsupervised Machine Learning?
Unsupervised Learning is a type of algorithm that learns patterns from unlabelled data.
What is Reinforcement Learning?
Reinforcement Learning is a type of machine learning technique that enables an agent to learn in an interactive environment by trial and error using feedback from its own actions and experiences.
What are the features and labels in Machine Learning?
The label is a thing we're predicting.
A feature is an input variable.
Why do we split data into train and test in Machine Learning?
While training the machine learning model, we split the entire dataset into two parts - the training and testing set. The training set is used to train the model whereas the testing set is used to evaluate the performance of the model on unseen data.
What is feature Scaling in Machine Learning?
Feature Scaling is a technique to standardize the independent features present in the data in a fixed range. If feature scaling is not done, then a machine learning algorithm tends to weigh greater values as higher and consider smaller values as the lower values, regardless of the unit of the values. This may affect the accuracy of the model.
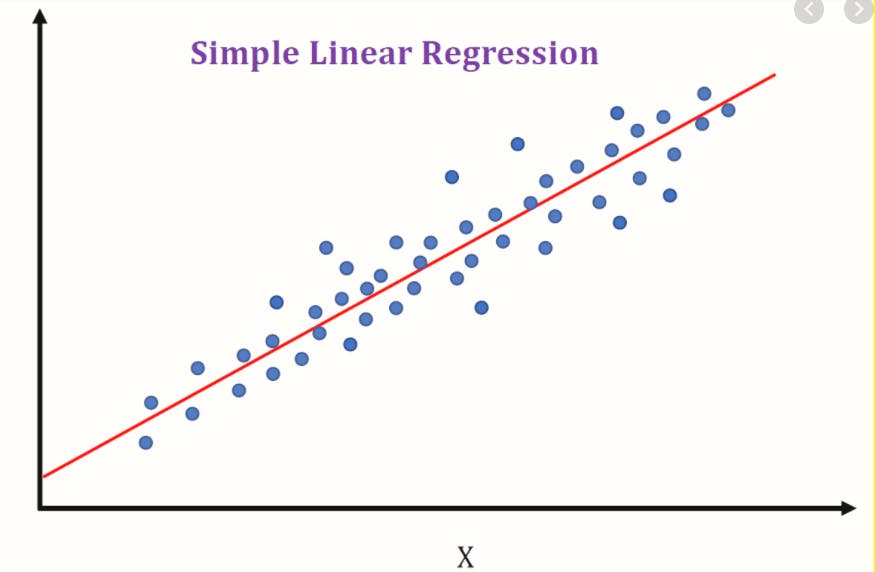
What is Regression?
Regression analysis consists of a set of machine learning methods, that allow us to predict a continuous outcome variable (y) based on the value of one or multiple predictor variables (x) and figure out the best fit line to that data.
Example:
Simple Linear Regression -
The best fit line in this case is a straight line.
y = mx + b. We need to find m and b with the help of regression.
Where :-
y -> Output
x -> Input
b -> y-intercept
m -> Slope
R-squared
It is used to determine the accuracy of the best fit line.
The error is the distance between the actual point and the point on the best fit line. We square the values so that we only need to deal with the positive values and also we want to penalize for outliers. The value ranges between 0 to 1.
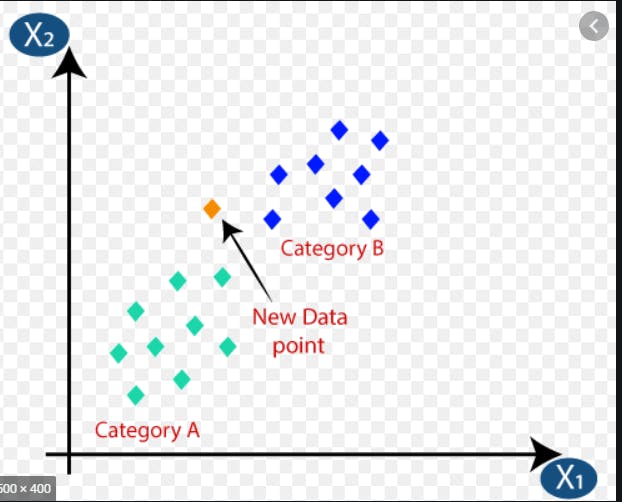
What is classification?
In machine learning, classification refers to a predictive modeling problem where a class label is predicted for a given example of input data. Examples of classification problems include - Given an example, classify if it is spam or not.
Example:
K-Nearest Neighbors -
K-NN algorithm assumes the similarity between the new data and available data and puts the new data into the category that is most similar to the available categories.
k -> Number of neighbors used to determine the label of new data based on distance from the new data point.
To calculate distance between 2 points, we can use- Euclidean Distance
Hope you found this helpful :)